10x Your Kubernetes Autoscaling Experience with Karpenter
I’ve been working with Kubernetes for a few years and it’s always jarring to experience the absolute disconnect between the cluster and its underlying infrastructure. I’ve used two tools so far for cluster management, the Cluster Autoscaler and Spotinst Ocean, and found both to be severely lacking.
Even a task as simple as providing a dedicated set of nodes for a group of users requires creating new node groups with custom labels and taints. It greatly limited the potential of Kubernetes and caused nightmares for replication because we’d have to capture application requirements partially in K8s YAML files and partly in the node group configurations. Not to mention, having too many node groups is an anti-pattern, so we couldn’t even commit to that completely.
I’d reached a state of acceptance that this was as far as we’d ever get with cluster management and that I’d just have to learn to live with it. But out of seemingly nowhere…
Enter Karpenter. The casual overachiever.
Can I request infrastructure resources directly from the pod spec? Uh-huh.
Can I use Kubernetes YAML files to define my infrastructure? Files that I could then deploy and manage with ArgoCD? Sure why not?
*Thinking of something wildly unrealistic* What about isolated, dynamic node groups that need nothing more than a node selector or node affinity specified in the workload definition? Pfft, trivial.
Honestly, I have whiplash from how Karpenter just upended everything I thought I knew about cluster autoscaling; there’s just no going back from such a K8s native infrastructure interface now.
The rest of the article goes over some high-level features of Karpenter followed by a short discussion of the concepts underlying Karpenter and some questions.
Features
Rapid node launch times
I’ve consistently seen unschedulable pods start execution in as little as 40 seconds. This speed is attributed to Karpenter determining instance types and provisioning them from the EC2 fleet API within a couple of seconds of the pod entering the unschedulable state.
Because of this, I’m already rethinking how I view autoscaling. What previously used to be a task of warming up node groups to handle workload spikes is now just a passing thought, “Eh, I’ve got Karpenter, it’ll be up in half a minute.”
Complete Control of Instance Provisioning
Using the provisioner spec or the pod spec, you can control everything about your EC2 instances from your K8s cluster. No more fiddling with infrastructure interfaces like the AWS console/CLI or Spotinst Ocean to provision node groups.
Cost Management
You can use Spot instances with the guarantee of fallback to On-Demand. Karpenter uses the EC2 Fleet API to ensure long-lived spot instances.
Kubernetes Native
Karpenter does a great job of being K8s native, and the more I think about it, the more I see that this was a really good design choice. Because they’ve taken three core components of pod specifications: resource requests, node-selectors, and node-affinity. And they’ve transformed it into an interface for your infrastructure by requiring you to do nothing but match specific labels. For example, specifying karpenter.k8s.aws/instance-family and c5 lets you limit your workloads to EC2 instances from the c5 instance family. Something that would've previously taken a node group and a cluster administrator to achieve.
Zero Third-Party Cost
Directly managing node groups on AWS is of course free. But as soon as you start using external tools like Spotinst Ocean, you run into charges. For example, Ocean reportedly charges you ~20% of the costs you save by using Spot instances [1, 2, 3]. This is a not-so-insignificant amount when you’re talking about running hundreds of Spot instances; and what exactly are you paying for? Not the instances themselves, you still have to pay AWS for that. Are you paying all that money just for them provisioning your Spot instances on your AWS account? Is it really worth that?
With Karpenter, you only use AWS native services like the EC2 Fleet API, so you pay for nada but your EC2 usage.
Deprovisioning and Consolidation
Karpenter can save costs by terminating empty and underutilized nodes.
Concepts

Karpenter Controller
This component looks for unschedulable pods and launches (provisions) EC2 instances (nodes) to schedule these pods.
When a node is unused for a pre-configured period of time, the controller also deletes (deprovisions) the corresponding nodes.
The controller also takes care of consolidation; when nodes are underutilized, it will move workloads around and deprovision nodes to more efficiently bin-pack your cluster.
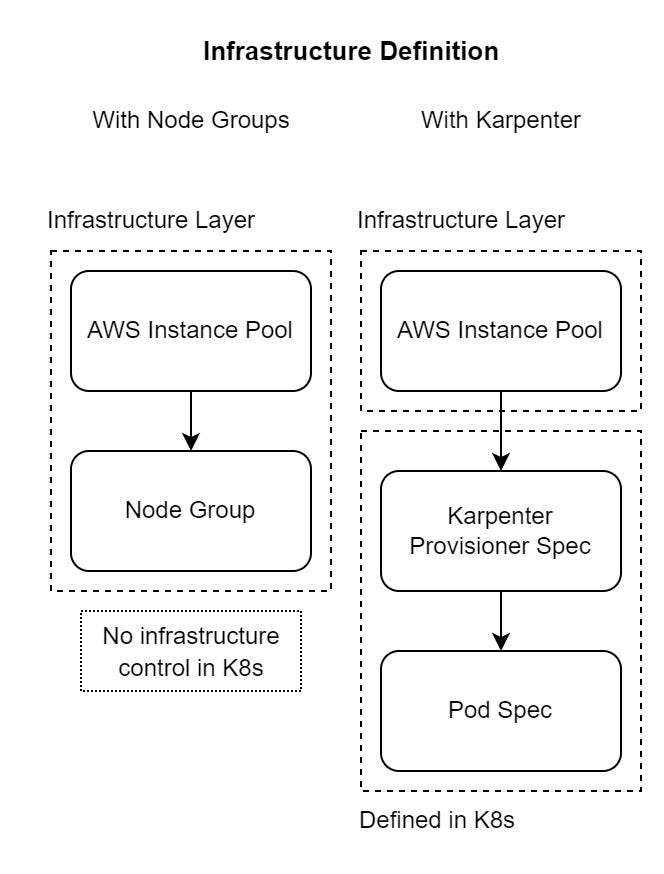
Layered Constraints
AWS has hundreds of instance types and dozens of instance families. Instead of forcing either the developer or the cluster administrator to take a call on the instance types and other attributes of the instances before the workload is even deployed, Karpenter allows both parties to specify constraints in different places.
An example:
The cluster administrator wants to keep the costs low and prevent instances with more than 50 GB of RAM from ever being provisioned for the cluster. So they specify this constraint in the ‘provisioner’.
The application developer finds this constraint too permissive for their application. Too many instance types have less than 50 GB of RAM, and the dev wants their pods to run only on a node that has between 15 and 25 GB of RAM, is network-optimized, and has a directly mounted SSD volume. Previously, they would have to put out a request to the cluster administrator, who would then provision a node group with a particular node label and taint, following which the app developer would be able to use it. Any follow-ups or modifications would have to be through the cluster admin.
With Karpenter, however, they can define this constraint directly in the pod specification of their workload using resource requests and node-selectors/node-affinity. Because the cluster admin has already enforced their constraints on the provisioner, they’re not involved in any way with this process. I’ve said this before, but this is game-changing! The infrastructure configuration resides inside your application YAML definition. And most importantly, you don’t have to bother your overworked infrastructure team for every little change, which means your development enters hyperspeed!

Constraints
Constraints are the key/value pairs specified in the provisioner or the pod spec that can control:
- Instance type — memory, CPU, architecture, and accelerators.
- Availability zone in which the instance is launched. (Topology)
- Where pods are deployed in relation to other pods — pod affinity/anti-affinity.
Provisioner (K8s Custom Resource)
Used at the cluster level, usually by the cluster administrator, to impose high-level constraints. The provisioner has a requirements field that allows the same constraints that can be specified in the pod spec, so instance types, topology, etc can be managed here. When pods then go into the unschedulable state, Karpenter tries to find a matching provisioner that can launch instances which will satisfy the constraints of the pod.
We can also specify the behaviour of the cloud provider, AWS for example. So things like the IAM InstanceProfile, AMI, User data, EC2 tags, etc can be configured here.
Provider
Even though Karpenter only supports AWS at present, it’s built to be cloud provider agnostic. So anything specific to a cloud is relegated to the provider definition. For AWS, this is the ‘AWSNodeTemplate’ Custom Resource, which can be referred to from the provisioner.
How does Karpenter schedule pods?
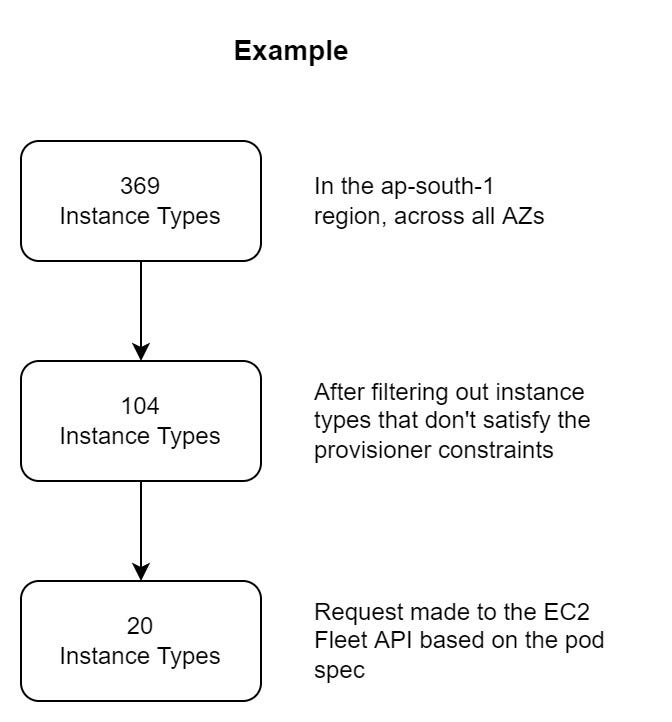
When there’s an unschedulable pod, Karpenter looks at the pod spec and determines the instance to be launched based on the resource requests and node-selectors/node-affinity.
It looks for a provisioner that is able to satisfy those constraints. When there are multiple provisioners eligible, Karpenter chooses one at random, so it’s advisable to make your provisioners mutually exclusive.
Twenty instance types are selected following this process, and a request is made to the EC2 fleet API to provision the necessary number of instances.
How are cost savings possible?
Karpenter allows you to use Spot instances with the option to fall back to On- Demand. So you get both low costs and guaranteed scheduling. If your provisioner spec or pod spec doesn’t limit the pool of possible instance types/zone by too much, you will get a spot instance 100% of the time. There are hundreds of EC2 instance types and multiple zones in every AWS region, which makes it practically impossible for the Spot market to ever completely “run out”.
How does Karpenter interact with the Spot Market?
It doesn’t! It interacts with the EC2 fleet API specifying the capacity-optimized-prioritized allocation strategy. This tells EC2 to provide spot instances that have the least likelihood of being interrupted so that the Spot instances on your cluster are not constantly being reclaimed by AWS. By letting the Fleet API do what it’s good at, Karpenter is saving itself from an impossible task — one of monitoring and keeping up with the Spot market in real-time.
How stable is Karpenter?
It’s more than stable enough for me to use it without worry in a volatile environment with regular and rapid autoscaling. But setting that aside, since I haven’t used it for very long, you can take the following points to the bank:
- Community engagement is high.
- It has well-recognized adopters using it in production.
- Development is highly active and any necessary features are either already available or in design, development or testing.
- AWS seems to be all in on it! In all honesty, this is pretty much the only assurance I needed. This project is here to stay.
Conclusion
Considering the issues that plague Kubernetes Cluster Scaling today, I see Karpenter’s revolutionary features gaining it immense traction over the course of the next year. As more people begin to use it, we will also start seeing its adoption by other cloud providers. If that doesn’t happen for some reason, they will at the very least adopt a similar model of bringing in infrastructure configuration into the cluster which can only be great news for anyone that uses managed Kubernetes (which seems to be the majority).
So a few years down the line, we’ll be looking at cluster scaling that will be baked into and native to every managed Kubernetes cluster.
Or so goes my dream.